
Так сколько голосов «украли» на президентских выборах — сотни тысяч или миллионы? Еще одно исследование: на этот раз — пессимистическое
Мы рассказываем честно не только про войну. Скачайте приложение.
В мае 2018 года «Медуза» опубликовала статью политолога, научного сотрудника Стэнфордского университета Кирилла Калинина о фальсификациях на президентских выборах. Как и многие другие исследователи, Калинин изучает математические и статистические методы, с помощью которых можно выявить нарушения при подсчете голосов; на этот раз он пришел к выводу, что на выборах президента России фальсификаций в пользу Владимира Путина было очень мало — меньше процента. Статистик, научный сотрудник университета Тюбингена Дмитрий Кобак и физик Максим Пшеничников провели несколько самостоятельных исследований президентских выборов — и уверены, что их коллега Калинин ошибся. «Медуза» публикует их ответы на наши вопросы, а также комментарий Кирилла Калинина.
Это продолжение дискуссии о фальсификациях на выборах президента России в 2018 году. Рекомендуем сперва прочитать текст Кирилла Калинина!
— Вы опубликовали несколько статей (1, 2, 3) со статистическим анализом российских выборов, где рассматривали странные пики около круглых значений явки и результатов. Что это за пики?
— Легче всего это объяснить на конкретном примере. На президентских выборах 2018 года, по официальным данным, явка составила 67,5%. При этом в России почти 100 тысяч избирательных участков, и для каждого из них мы можем подсчитать явку. Вот как выглядит распределение всех участков по явке:
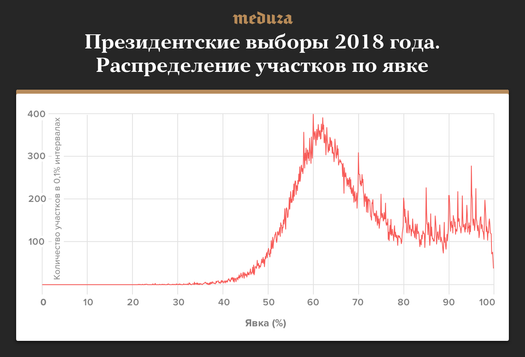
На этом графике видно, что больше всего участков с явкой примерно 62%, но распределение довольно широкое: попадаются участки с явкой от 40 до 100%. Бросающаяся в глаза особенность этого графика — узкие пики на высоких значениях явки. Самые высокие пики находятся на круглых значениях явки (70%, 80%, 90%), пики поменьше хорошо видны на целых значениях (например, 91,0%, 92,0%, 93,0% и т. д.). Это означает, что участков с целой явкой (например, 93,0%) значительно больше, чем с нецелой (92,9% или 93,1%).
— Когда речь идет о фальсификациях на выборах, постоянно говорят о пиках. Можете объяснить, чем они так важны?
— Смотрите: в избирательном протоколе явка не фигурирует, туда записываются (среди прочих цифр) только общее число зарегистрированных избирателей и число выданных бюллетеней. Предположим, на каком-то участке зарегистрировано 1757 избирателей (обычный размер для городского избирательного участка). Чтобы получить явку 93,0%, там должно быть выдано ровно 1634 бюллетеня: одним бюллетенем больше или меньше, и округленный до десятых долей процента показатель явки составит уже 92,9% или 93,1%. Ничего особенного в числе 1634 нет; особенность возникает только при его делении на 1757. Избыток участков с целой явкой можно объяснить только одним образом: кто-то сначала придумал желаемую явку, и только потом подогнал количество «выданных» бюллетеней под этот процент; и так произошло сразу на многих участках. Если бы результаты выборов подсчитывались честно, то «круглая» цифра явки имела бы не больше и не меньше шансов, чем любая другая «не-круглая», и пику на 93,0% было бы неоткуда взяться.
Если посмотреть на распределение процента голосов, которые набрал Путин, то график будет похожий, с большим количеством пиков на целых процентах.
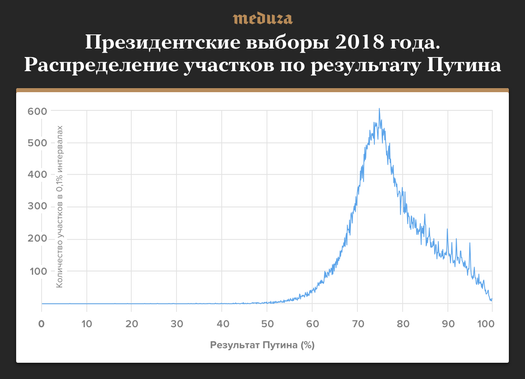
Причем, опять-таки, официальный результат считается только на федеральном уровне, то есть голоса за кандидата складываются по всем участкам и делятся на общее число голосовавших. Явка и результат победителя на уровне отдельного участка официально нигде не фигурируют — и тем не менее в распределении результатов проявляется тяга к круглым значениям. Эта тяга легко объяснима, если предположить, что на многих участках количество голосов подгонялось под красивый процент явки или «за Путина». Который и наверх сообщить легко и приятно.
Мы не видим никакого другого объяснения пикам на целых процентах, кроме манипуляции голосами избирателей. В этом их отличие от многих других статистических аномалий, которые могут выглядеть крайне подозрительно, но, строго говоря, доказательствами не являются — всегда можно найти «альтернативное» объяснение.
— Кирилл Калинин утверждает, что на выборах 2018 года эта аномалия несколько уменьшилась. Это действительно так?
— Нет, это не так. В нашей статье 2016 года мы предложили метод подсчета «целочисленной аномалии»: на сколько больше участков показали целый процент явки или результата победителя (т.е. Путина, Медведева или «Единой России»), чем можно было бы ожидать при честном подсчете. Грубо говоря, это сумма высот всех пиков на целых процентах. Вот как выглядит график целочисленной аномалии (из нашей статьи этого года) на всех федеральных выборах с 2000 по 2018 год:
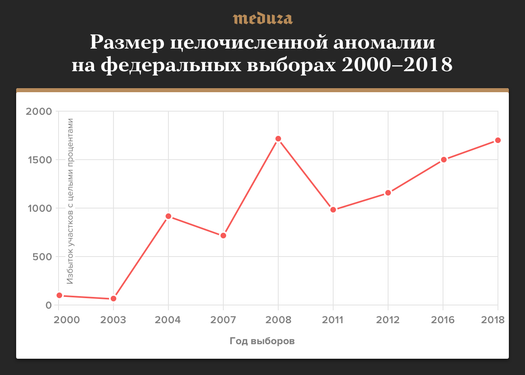
В 2000 и 2003 годах аномалия близка к нулю — целочисленных пиков тогда не было (а фальсификации, по-видимому, были минимальны). В 2004-м аномалия резко подскочила до 1000 участков, в 2008-м достигла 1750 участков (почти 2% от их общего числа) — и в 2018-м снова вернулась на этот рекордный уровень.
Кирилл Калинин в публикации на «Медузе» ссылается на статью Розенаса (2017), который вслед за нами предложил похожий метод подсчета суммарной высоты пиков. Розенас анализирует только пики в распределении результата победителя, но почему-то не рассматривает пики в распределении явки. С учетом этого ограничения, его метод хорошо согласуется с нашим.
— Калинин оценивает количество сфальсифицированных голосов на последних выборах в 320 тысяч, опираясь на статистическую модель Уолтера Мебейна. Вы эту модель критиковали. Почему?
— Уолтер Мебейн использует без каких-либо изменений модель Петера Климека, которая была предложена в статье 2012 года. Показать, как работает эта модель, удобно с помощью двумерной гистограммы: по горизонтали тут отложена явка, по вертикали отложен результат победителя, а цвет каждого пикселя показывает количество участков с такой явкой и результатом — чем краснее, тем больше там участков. Вот, например, как это выглядит в случае выборов 2011-12 годов (левая колонка):
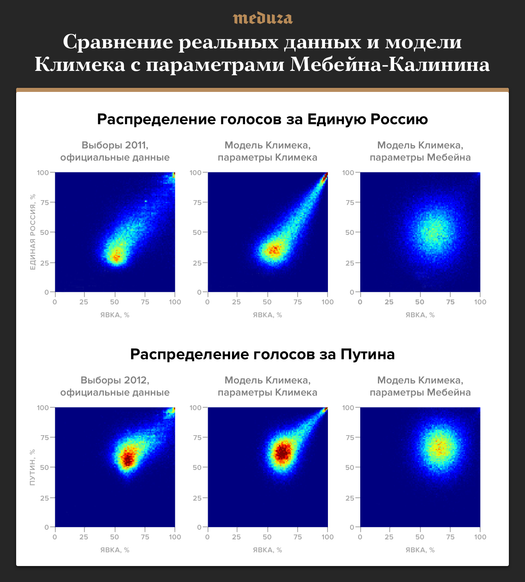
Согласно модели Климека, «настоящие» явка и результат победителя соответствуют сгустку участков в левой нижней части распределения. Вбросы и перебросы бюллетеней в пользу победителя приводят к увеличению явки и одновременному увеличению результата победителя, в результате чего исходный сгусток «размывается» вправо и вверх (средняя колонка). Модель описывает этот процесс с помощью восьми параметров: четыре параметра описывают честные результаты, и еще четыре — характер фальсификаций и их размер. Для средней колонки на нашей иллюстрации мы использовали значения параметров из статьи Климека.
Мебейн в своем тексте 2016 года предложил альтернативный метод поиска значений этих восьми параметров, которые лучше всего согласуются с наблюдаемыми данными, а затем вместе с Калининым применил этот метод ко всем российским выборам с 2000 года. К сожалению, ни в одной из этих статей не показано, насколько хорошо (или плохо) их параметры описывают реальные данные. Мы взяли значения параметров из их текста, провели вычисления и можем наглядно продемонстрировать, что на практике метод Мебейна не приводит к согласию между моделью и исходными данными (правая колонка). Легко видеть, что параметры Мебейна не имеют никакого отношения к реальности, в отличие от параметров Климека. Иными словами, процедура Мебейна работает некорректно, и поэтому никакие выводы на ее основании делать невозможно в принципе.
Чтобы увидеть неадекватность параметров Мебейна-Калинина, не обязательно даже проводить вычисления. Можно просто посмотреть в таблицу параметров в их тексте 2017 года; они, например, оценивают «честную» явку на выборах 2008 года в 75,5%. При этом официальная явка в 2008 году была 69,8%, то есть честная явка по Мебейну значительно превышает официальную цифру. Такого в принципе не может быть, поскольку фальсификации в модели Климека могут только увеличивать явку, а не уменьшать ее.
Таким образом, мы можем констатировать, что выводы Мебейна и Калинина основаны на недоразумении.
— То есть оценка Калинина в 320 тысяч фальсифицированных голосов занижена?
— С нашей точки зрения, это число совершенно неправдоподобно.
Повторим еще раз: модель Климека предполагает, что «честные» явка и результат победителя соответствуют главному сгустку на двумерной гистограмме. Мы уже показывали распределение участков по явке на выборах 2018 года (см. первый график в этой статье). Центр «главного сгустка» там находится примерно на явке 62%. В модели Климека это и является оценкой настоящей явки. Это означает, что согласно модели Климека, за победителя было вброшено (67,5% — 62%) × 109 млн = 6 миллионов голосов. Оценка Калинина в 320 тысяч, очевидно, основана на совершенно неадекватных значениях параметров модели, которые никак не соответствуют реальным данным.
Впрочем, в отличие от Мебейна и Калинина, мы не склонны слишком сильно полагаться на модель Климека. Она, например, никак не учитывает географическую неоднородность, которая в России очень сильна: честные результаты, например, в Москве и в Крыму заметно отличаются. Мы считаем, что оценку общего количества фальсификаций можно дать, только аккуратно разбираясь с каждым регионом по отдельности. Мы эту работу не проделывали, поэтому воздерживаемся от конкретных оценок. Но из изложенного выше ясно, что общее число должно измеряться в миллионах голосов.
— А ваше собственное исследование пиков на круглых процентах позволяет как-то оценить общий объем фальсификаций?
— Если мы просто просуммируем избыток голосов за Путина на участках с целочисленными результатами, то получится 1,75 миллиона. Понятно, что значительная часть этого числа — фальсификации: зачем было бы рисовать красивые проценты, если не увеличивать результат победителя? Однако следует иметь в виду, что, с одной стороны, не все бюллетени на участках с целыми процентами обязательно поддельные, а, с другой стороны, не все участки с манипуляциями дают целые проценты. Так что общий объем фальсификаций так подсчитать не получится.
Тем не менее, мы считаем, что целочисленная аномалия — это только верхушка айсберга фальсификаций, которая «торчит на поверхности» и видна невооруженным взглядом.
Что на это говорит Кирилл Калинин?
Хотя метод Розенаса и анализирует только пики в распределении результата победителя, однако, использует явку в качестве основы для расчета модели — это позволяет решить проблему двойного счета фальсификаций. В случае отдельного анализа распределений явки и голосования, как это делают Пшеничников и Кобак, эта проблема может стоять достаточно остро. Также ошибочно полагать, что расчеты, полученные с помощью метода Мебейна, сводимы к результатам расчетов метода Климека. С точки зрения своих статистических свойств, модель Мебейна отличается от модели Климека, поэтому любые сравнения с помощью двумерных гистограмм некорректны. Выявленные же авторами расхождения между официальной явкой и «честной» явкой связаны, главным образом, с ошибкой агрегирования: оценка «честной» явки в модели Мебейна строится не на подсчете общего числа поданных в стране голосов, а на расчете средней явки по явкам на всех участках в стране. И, конечно, трудно не согласиться, что серьезное внимание и в наших расчетах, и в расчетах наших коллег должно уделяться географической неоднородности.
Ничего не поняли? Не страшно. Вот короткое объяснение. Калинин утверждает, что в пользу фаворита президентской гонки вбросили лишь несколько сотен тысяч голосов. По мнению Кобака и Пшеничникова, расчеты Калинина некорректны, а на выборах «украли» несколько миллионов голосов. Ученые используют разные методы подсчета фальсификаций, поэтому их результаты сильно различаются. Кто из них звучит убедительнее, решать вам!
Александр Борзенко, Денис Дмитриев
(1) Расчеты
Комментарий Кобака и Пшеничникова: «Все наши расчеты для этой статьи можно найти тут. Мы исключаем из рассмотрения участки с явкой 100%, т. к. это либо временные участки, для которых явка не определена, либо особые участки вроде воинских частей».(2) Что такое 93,0%?
Комментарий Кобака и Пшеничникова: «Говоря об участках с явкой 93,0%, мы имеем в виду все участки с явкой 93,0 ± 0,05%, т. е. все числа здесь округлены до десятых долей процента».(3) Распределения явки и процента победителя
Комментарий Кобака и Пшеничникова: «Распределения явки и процента победителя на всех выборах с 2000 по 2018 можно посмотреть здесь».(4) Соответствие методу Розенаса
Комментарий Кобака и Пшеничникова: «Смотрите таблицу № 2 в статье Розенаса и красную линию на графике № 2 в нашей статье 2018 года».(5) Данные для проверка метода Мебейна
Комментарий Кобака и Пшеничникова: «Смотрите таблицу № 2 в тексте Мебейна и Калинина (2017). Два недостающих в этой таблице параметра нам любезно прислал Уолтер Мебейн».