
Исследователь из Стэнфорда считает, что фальсификаций на выборах президента России было очень мало. Как он это вычислил?
Мы рассказываем честно не только про войну. Скачайте приложение.
7 мая 2018 года пройдет инаугурация президента России Владимира Путина, победившего в марте на выборах главы государства. Наблюдатели и журналисты в день голосования зафиксировали множество нарушений и аномалий, но Путин назвал прошедшие выборы «самыми чистыми в истории нашей страны». Стипендиат Гуверовского института Стэнфордского университета (2017-2018), доктор политических наук Мичиганского университета Кирилл Калинин, специализирующийся на изучении электоральных фальсификаций, обнаружил нарушения на мартовских выборах — преимущественно вбросы голосов в пользу Путина. «Медуза» попросила Кирилла Калинина рассказать о предварительных результатах исследования, применявшемся методе и его ограничениях.
Фальсификаций на выборах президента в 2018 году было много?
Согласно нашим вычислениям, общий объем фальсификаций мог составить порядка 320 тысяч голосов, что меньше 1% от числа проголосовавших за Путина. При этом фальсификациями могли быть охвачены 4% участков. По сравнению с думскими выборами 2016 года, когда, по нашим подсчетам, украли два миллиона голосов, масштаб оказался сравнительно небольшим — его можно сопоставить с выборами 2004-го.
Вот рейтинг регионов, где фальсификаций было больше всего:
- Краснодарский край
- Кемеровская область
- Башкортостан
- Ямало-Ненецкий АО
- Ставропольский край
- Татарстан
- Северная Осетия
- Дагестан
Анализ показал, что результаты фальсифицировали чаще всего обычным для России способом — вбрасывали заполненные бюллетени в пользу победившего кандидата.
Как были подсчитаны фальсификации?
С помощью статистической, так называемой «конечной смешанной модели» (finite mixture model), разработанной Волтером Мебейном в 2016 году. В ее основу легла модель, которую создал Питер Климек и его коллеги в 2012-м.
Многие слышали, что исследователи выборных фальсификаций часто смотрят, как показатели голосования и явки распределяются на графике. По нормальному закону распределения график данных с честных выборов может принимать форму колокола — с одним «горбом».
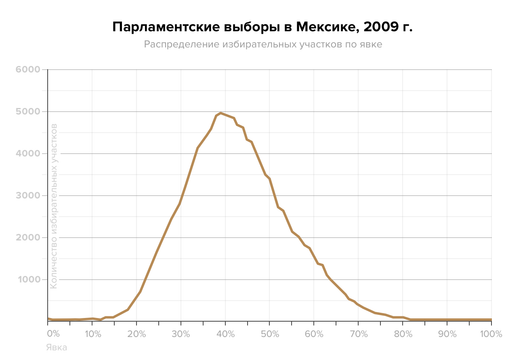
Если на графике появляется больше одного «горба», это повод задуматься.
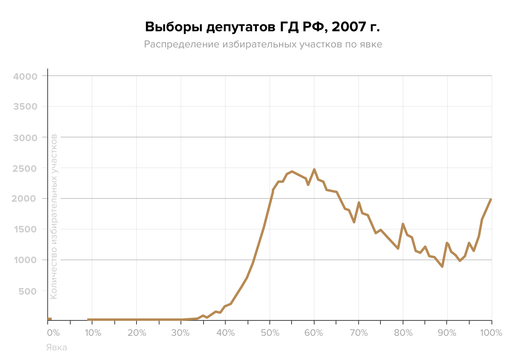
Модель Мебейна помогает исследователям понять, откуда взялись дополнительные «горбы» — фальсификация это или какая-то другая аномалия, не связанная с нарушением закона.
Что это еще за аномалии?
Самые разные. На возникновение «горбов» помимо фальсификаций могут повлиять особенности электорального поведения в различных регионах и районах страны, формирование предвыборных коалиций, существование малых поселений и военных гарнизонов и так далее. К примеру, в Канаде или Германии распределения голосования за партии имеют разнообразные причудливые очертания, которые без учета социально-культурной неоднородности страны можно было бы запросто списать на фальсификации.
Как работает модель Мебейна?
В качестве исходных данных для расчета модели берутся три переменные, с помощью которых можно рассчитать и явку избирателей, и процент голосов, полученный победителем:
- общее число зарегистрированных избирателей,
- общее число проголосовавших избирателей,
- число избирателей, проголосовавших в пользу победившего кандидата.
Модель выявляет аномальное распределение голосования и явки, но не приравнивает все аномалии к фальсификациям. Согласно модели Мебейна, на каждом из избирательных участков, попавших в зону аномалии, выборы могли пройти по одному из трех сценариев:
- чистого голосования,
- «инкрементных фальсификаций» (incremental fraud) — переброса голосов от проигравшего кандидата в пользу победителя,
- «предельных фальсификаций» (extreme fraud) — вбросов голосов в пользу победителя.
В случае инкрементных фальсификаций явка на избирательном участке оказывается слегка искусственно завышенной, а процент голосов, полученных победителем, увеличивается. В случае предельных фальсификаций пропорционально увеличиваются явка и голоса за победителя.
Модель позволяет оценить, с какой вероятностью на каждом избирательном участке в конкретном регионе (избирательном округе) могло быть либо честное голосование, либо вбросы или подтасовка результатов, а также подсчитать общее число украденных голосов. Основная ценность модели в том, что аномалии можно проверить на любом интересующем нас уровне, от отдельных участков и регионов до страны в целом.
У этой модели есть какие-то ограничения?
Да, ограничения есть. Модель предполагает, что только у победившего кандидата была возможность повлиять на исход выборов путем фальсификаций — подтасовок и вбросов голосов. Модель хорошо описывает механизм фальсификаций для мажоритарных систем, где есть явный победитель (президентские выборы, одномандатные округа), ее применение для пропорциональной избирательной системы может быть затруднено из-за сложности определения явного победителя. Кроме того, модель не может выявить те фальсификации, которые не приводят к появлению дополнительных «горбов» на графиках распределения голосов и явки.
Модель Мебейна позволяет лишь оценить масштаб аномалий, которые с высокой степенью вероятности могут трактоваться в качестве фальсификаций. При этом она не претендует на универсальность своих оценок и тем более не служит доказательством существования настоящих фальсификаций. Модель скорее является индикатором. Для утверждения существования фальсификаций необходимо получение неопровержимых доказательств нарушений.
Точность метода зависит от способности модели успешно воспроизвести и оценить реальный механизм фальсификаций. Модель хорошо зарекомендовала себя на множестве выборов: например, зафиксировала нарушения на парламентских выборах в Турции в июне и ноябре 2015 года (правящая партия сначала потеряла, а затем вернула большинство мест в парламенте), не нашла их на президентских выборах в Австрии весной 2016-го (в итоге они были отменены из-за формальных нарушений регламента, но не из-за фальсификаций) и выявила фальсификации на президентских выборах в Кении в августе 2017-го (выборы аннулированы Верховным судом Кении из-за множества нарушений).
Есть и другие методы, позволяющие оценить наличие фальсификаций. Например, оценка неожиданных пиков около круглых значений явки. Согласно нашим дополнительным расчетам, на прошедших выборах процент аномальных участков, расположенных на пиках круглых значений явки и голосования, составил 0,66%, что по уровню сопоставимо с 2004 годом (для сравнения: 0,06% в 2000-м и 0,85% в 2016-м). Некоторые методы стали частью веб-приложения по исследованию выборов (Election Forensics Toolkit). Конечно, если разные методы говорят о присутствии электоральных аномалий, можно c большей уверенностью говорить о том, что выборы не были чистыми.
Есть альтернативные расчеты от Сергея Шпилькина. Они показали куда более высокий уровень фальсификации. Чем можно объяснить разницу оценок?
Это сложный вопрос, требующий отдельного изучения. Разница в наших оценках фальсификаций действительно колоссальная. Связана она, скорее всего, с разницей между нашими подходами.
По расчетам Сергея Шпилькина, на президентских выборах победивший кандидат получил 6,5 миллиона голосов за счет вбросов и 1 миллион голосов за счет переброса их от других кандидатов.
В отличие от нашего подхода, который строится на модели, воспроизводящей механизм перетекания голосов в пользу победившего кандидата, Сергей Шпилькин предлагает свой алгоритм расчета фальсификаций на базе эмпирического распределения явки и голосования, который не базируется на какой-либо модели. Шпилькин исходит из идеи, что люди ходят на выборы и голосуют примерно похожим образом, поэтому голоса должны распределяться в виде одного «горба», отчасти напоминающего нормальное распределение. Согласно этому подходу, даже в случае серьезных фальсификаций «чистый горб» всегда можно распознать, а извлеченная из него информация поможет рассчитать общий масштаб фальсификаций.
В прошлый раз, при анализе выборов 2016 года, между нашими подходами также обнаружилась существенная разница в оценках. Дополнительный анализ показал, что наши подходы более или менее согласуются при ранжировании регионов по выраженности фальсификаций, однако по-разному оценивают их масштаб.
Я не берусь утверждать, чьи расчеты ближе к истине — наши или Сергея Шпилькина. Но у нашего метода есть важное преимущество: мы можем получить оценки на уровне отдельно взятых участков, и это позволяет нам при желании сравнить полученные данные с отчетами наблюдателей. В случае значительных расхождений между расчетными и наблюдаемыми фальсификациями отдельные части модели всегда могут быть пересмотрены. В любом случае, мы лишь в самом начале длинного пути по разработке совершенной статистической модели, проливающей свет на масштаб и характер электоральных фальсификаций.
Сергей Шпилькин отказался комментировать работу Кирилла Калинина, назвав модель Мебейна «безумно усложненной и совершенно нежизнеспособной». Но позже результатами своих альтернативных подсчетов с «Медузой» поделились статистики Дмитрий Кобак и Максим Пшеничников. По их выкладкам, на выборах «украли» несколько миллионов голосов.
Кирилл Калинин
(1) Одногорбное распределение на выборах в России
В пользу допущения одного «горба» отчасти говорит одно важное обстоятельство: если на думских выборах в декабре 2011 года распределение голосования демонстрировало выраженную аномальность, то буквально через несколько месяцев после массовых протестов и роста прозрачности выборов распределение получилось более одногорбным и нормальным. Иными словами, вполне возможно, что люди и правда голосуют куда более однородно, чем мы думаем. Это наблюдение отчасти подтверждает обоснованность допущения о нормальности распределения для модели Мебейна и его одногорбности для подхода Шпилькина.